Chapter 07
분산 시스템을 위한 유일 ID 생성기
다중 마스터 복제, UUID, 티켓 서버, 트위터 Snowflake 방식 비교. 시간·서버 ID·일련번호 비트 배치.
분산 ID는 4마리 토끼 문제 — 답은 “비트를 쪼개 쓰는” Snowflake
분산 환경에서 ID를 만들려면 독립성 · 유일성 · 시간순 정렬 · 작은 크기(64비트)를 동시에 만족해야 한다. 4가지 후보를 비교하면 셋은 한 측면씩 희생하고, Snowflake가 64비트를 시간/장소/순서로 분할해 네 요구사항을 한꺼번에 푼다. 운영 디테일은 시계 동기화와 머신 ID 부여 두 가지로 압축된다.
- ① 4가지 후보 — 다중 마스터 복제 / UUID / 티켓 서버 / Snowflake. 평가 기준은 5가지 요구사항.
- ② Snowflake의 비트 분할 — 41 + 5 + 5 + 12 (timestamp + DC + 머신 + 일련번호).
- ③ 운영의 함정 — NTP·시계 역행 처리 + 머신 ID 부여 방식 + 비트 재분배.
왜 분산 ID가 어려운가 — 요구사항 5가지
후보들을 비교하기 전에 “우리 ID는 무엇이어야 하는가” 기준부터 잡는다. 면접에서 PM/면접관에게 던지는 질문 묶음 ↓
면접에서 확정할 요구사항
- 유일성 — 시스템 전역에서 ID가 절대 겹치면 안 되는가? (보통 “예”)
- 숫자 형태인가? — 정수만 허용? 문자열도 OK?
- 크기는 얼마나? — 64비트(BIGINT)에 들어가야 하는가?
- 시간 순으로 정렬되어야 하는가? — 타임라인·피드처럼 “나중에 만든 ID가 더 커야” 하는 요구가 있는가?
- 발급 속도/규모 — 초당 몇 개? 머신 몇 대?
이 챕터의 표준 요구사항
- ID는 유일해야 한다
- ID는 숫자형 값이어야 한다
- ID는 64비트로 표현될 수 있는 값이어야 한다
- ID는 발급 일자에 따라 정렬가능해야 한다
- 초당 10,000개 이상의 ID를 만들 수 있어야 한다
→ 이 다섯 가지가 이후 후보들을 평가하는 잣대가 된다. 다음 섹션의 비교 표(✅/❌)는 모두 이 요구사항 묶음 기준으로 매긴 점수다.
4가지 후보를 한 자리에서 비교하기
분산 ID 생성에 자주 쓰이는 네 가지 방식 — 다중 마스터 복제 / UUID / 티켓 서버 / Snowflake. 셋은 위 5가지 요구사항 중 한 측면을 희생하고, Snowflake만이 모두 만족한다.
다중 마스터 복제 (Multi-master Replication)
특징
- 데이터베이스의
auto_increment기능을 활용 - 다음 ID 값을 구할 때 1만큼 증가시키는 것이 아니라, 사용 중인 데이터베이스 서버 수(k)만큼 증가시킨다.
- 예: 서버가 2대라면 한 서버는 1, 3, 5, 7…을, 다른 서버는 2, 4, 6, 8…을 발급
- 각 마스터 서버가 독립적으로 ID를 생성할 수 있어 규모 확장성 확보를 시도하는 방식
장점
- 데이터베이스의 기본 기능을 그대로 활용하므로 구현이 비교적 단순
- 단일 데이터베이스 서버에 ID 생성을 의존하지 않으므로 단일 장애점(SPOF)을 어느 정도 회피
단점과 그 근본 원인
- 여러 데이터센터에 걸쳐 규모를 늘리기 어려움 — 유일성을 위해 서버 간 동기화가 필요한데 거리(지연)가 이를 방해
- 시간 흐름에 따라 ID가 커지지 않음 — ID에 시간 정보가 없고 각 서버가 독립 시퀀스를 사용하기 때문
- 서버 추가/제거 시 동작이 깨짐 — 발급 규칙이 “전체 서버 수(k)”에 결합되어 있어 토폴로지 변경에 민감
| 단점 | 근본 원인 |
|---|---|
| 다중 데이터센터 확장 곤란 | 유일성을 위해 서버 간 동기화가 필요한데 거리(지연)가 이를 방해 |
| 시간순 보장 안 됨 | ID에 시간 정보가 없고 각 서버가 독립 시퀀스를 사용 |
| 서버 증감 시 취약 | 발급 규칙이 “전체 서버 수(k)”에 결합되어 있어 토폴로지 변경에 민감 |
UUID (Universally Unique IDentifier)
- 128비트(16바이트) 짜리 식별자
- 표기 예:
09c93e62-50b4-468d-bf8a-c07e1040bfb2 - 각 서버가 독립적으로 만들 수 있음 → 서버 간 조율 불필요
- 대표 종류: UUIDv1(타임스탬프 + MAC), UUIDv4(무작위, 가장 널리 쓰임)
장점
- 단순 — 서버 간 조율 불필요. 라이브러리 한 줄 (
uuid.uuid4(),crypto.randomUUID()) - 규모 확장이 쉬움 — 각 서버가 독립적으로 발급
- SPOF 없음 — 중앙 ID 서버가 존재하지 않음
단점
- 128비트로 길다 — 책의 요구사항(64비트)을 어김. 저장 공간·인덱스·네트워크 부담
- 시간 순서로 정렬되지 않음 — UUIDv4는 무작위. DB 인덱스(B-Tree)도 무작위 삽입에 약함
- 숫자 형태가 아님 — 16진수 + 하이픈 문자열
티켓 서버 (Ticket Server)
“ID 생성을 한 군데에서만 하면, 유일성 문제는 자동으로 풀린다.”
플리커(Flickr)가 분산 기본 키 생성에 사용한 방식. auto_increment 기능을 갖춘 단일 서버를 두고, 모든 ID 요청이 그곳을 거치게 한다.
장점
- 유일한 숫자 ID가 자연스럽게 발급됨
- 구현이 매우 단순 — DB 한 대 + auto_increment
- 시간 순으로 단조 증가 — 모든 발급이 한 서버를 거치므로
단점
- 단일 장애점(SPOF) — 티켓 서버가 죽으면 의존하는 모든 시스템이 ID를 못 받음
- 여러 대로 늘리면 다중 마스터 복제 문제로 회귀
- 트래픽이 매우 커지면 병목
트위터 Snowflake — 발상의 전환
“ID 자체를 만들지 말고, 비트를 나눠 쓰자.”
앞의 셋은 모두 한 측면을 희생했다 — 다중 마스터는 협조 실패, UUID는 크기·정렬, 티켓 서버는 SPOF·병목. Snowflake는 발상을 바꾼다 — 64비트 ID를 의미 있는 조각들로 분할해서, 각 조각이 다른 역할을 맡게 한다. 그러면 ID 하나에 “시간순 정렬”, “서버 간 독립성”, “유일성”을 동시에 담을 수 있다. 깊은 내용은 다음 섹션에서.
네 방식 종합 비교
5가지 요구사항(+다중 DC)으로 매긴 점수표.
| 요구사항 | 다중마스터 | UUID | 티켓서버 | Snowflake |
|---|---|---|---|---|
| 유일성 | △ | ✅ | ✅ | ✅ |
| 시간순 정렬 | ❌ | ❌ | ✅ | ✅ |
| 64비트 | ✅ | ❌ | ✅ | ✅ |
| SPOF 없음 | ✅ | ✅ | ❌ | ✅ |
| 확장성 | ❌ | ✅ | ❌ | ✅ |
| 다중 DC | ❌ | ✅ | ❌ | ✅ |
Snowflake 깊이 보기 — 비트 구조와 동작
“비트를 나눠 쓰자”는 발상이 어떻게 64비트 안에서 구체적으로 펼쳐지는지 본다. 영역 4개 + 부호 비트 1개로 나뉜다.
64비트 구조
합계 64비트. 부호 비트는 항상 0이라 양수가 보장된다. 폭은 비트 수에 비례한다.
| 영역 | 비트 | 역할 |
|---|---|---|
| 부호 비트 | 1 | 항상 0 (음수 방지) |
| 타임스탬프 | 41 | 기준 시각(epoch)부터의 ms 단위 경과 시간 |
| 데이터센터 ID | 5 | 최대 2⁵ = 32개 데이터센터 식별 |
| 머신 ID | 5 | 데이터센터당 최대 32개 머신 식별 |
| 일련번호 | 12 | 같은 ms 안에서 1씩 증가 (4096개까지) |
각 영역이 푸는 문제
① 타임스탬프(41비트) — “시간순 정렬”
- 단위는 밀리초(ms)
- 41비트 → 약 69년 동안 사용 가능 (2⁴¹ ms ≈ 69년)
- ID 최상위 비트들이 시간이라서, ID를 그냥 정렬하면 자동으로 시간 순서가 됨
- → UUID의 가장 큰 약점(정렬 불가)을 해결
② 데이터센터 ID(5비트) + 머신 ID(5비트) — “서버 독립성”
- 합쳐서 10비트 = 최대 1024대의 머신을 구분
- 각 머신은 자기에게 부여된 ID를 그대로 사용 → 서버 간 통신·동기화 불필요
- → 다중 마스터 복제의 약점(서버 간 협조 실패)과 티켓 서버의 약점(SPOF) 동시 해결
③ 일련번호(12비트) — “같은 ms 내 충돌 방지”
- 같은 머신이 같은 ms 안에서 ID를 여러 개 만들 때 0부터 1씩 증가
- 12비트 → ms당 4096개까지 발급 가능 → 머신당 초당 약 400만 개
- 다음 ms로 넘어가면 0으로 리셋
- → 동일 시점·동일 머신 충돌 방지
동작 흐름
- 현재 ms 타임스탬프를 41비트에 기록
- 미리 부여받은 데이터센터 ID(5비트) + 머신 ID(5비트)를 그대로 끼워넣음
- 이 ms에서 몇 번째 발급인지 일련번호(12비트)에 기록 후 1 증가
- 네 조각을 합쳐 64비트 정수로 반환
만약 일련번호가 4096을 넘으면? → 다음 ms까지 잠시 대기한 뒤 0부터 다시 시작. 자세한 운영 디테일은 다음 섹션에서.
운영의 함정 ① — 시계
비트 구조를 정했으니, 이제 실제로 ID를 발급할 때 생기는 운영 문제를 본다. 타임스탬프 영역에서만 다루어야 할 이슈가 네 가지다.
① Epoch 선택 — “언제부터의 시간인가”
- 41비트 타임스탬프는 특정 기준 시각(epoch)부터의 ms 경과 시간이다.
- UNIX epoch(1970-01-01)를 그대로 쓰면 41비트 중 이미 상당량을 소진한 상태로 시작 → 남은 사용 기간이 짧아짐
- 그래서 보통 서비스 출시 시점을 custom epoch로 지정 한다 — 트위터: 2010-11-04, 디스코드: 2015-01-01
- → 약 69년 동안 사용 가능
② 시계 동기화 (NTP)
- Snowflake는 각 머신의 로컬 시계에 의존한다 → 여러 머신의 시계가 어긋나면 ID 시간순 정렬도 어긋남
- 모든 노드는 NTP(Network Time Protocol)로 시계를 맞춰야 함
- 그래도 ms 수준의 미세한 어긋남은 남을 수 있어, 분산 환경에서전역 시간 순서를 “정확히” 보장하긴 어렵다 — “대체로 시간순” 정도가 현실적인 보장 수준
③ 시계 역행(Clock Going Backward) — 가장 큰 함정
NTP 동기화나 관리자 실수로 시계가 과거로 점프하면?
- 과거 타임스탬프 + 같은 머신 ID + 같은 일련번호 = 이미 발급된 ID와 완전히 동일한 값 발급 → 충돌
- 대처 방법:
- 마지막 발급 ms를 메모리에 보관 → 새 요청의 현재 ms가 그보다 작으면 발급 거부 또는 대기
- 대기 vs 거부는 정책 선택 — 짧은 역행이면 따라잡을 때까지 sleep, 긴 역행이면 알림 발생시키고 거부
- 재시작 시: 마지막 발급 ms를 영속 저장(파일/Redis)해두고 부팅 시 현재 시각이 그보다 크다는 걸 확인 → 더 작으면 그 시각이 될 때까지 대기
시계 문제는 분산 시스템에서 “당연히 잘 되겠지” 가장 잘못 가정되는 영역이다. Snowflake가 단순해 보여도, 실무에서 사고가 나는 지점은 거의 항상 여기.
④ 머신 시계 의존을 다루는 기법들 (간단 정리)
“물리 시계를 못 믿는다”는 분산 시스템의 고전적 문제고, 이를 다루는 기법이 여러 개 있다. Snowflake도 결국 이 도구들 중 일부를 골라 쓰는 것이다.
| 기법 | 아이디어 | 대표 사용처 |
|---|---|---|
| NTP 동기화 | 외부 시간 서버와 주기적으로 맞춤 — 가장 기본 | 거의 모든 서버 |
| 단조 시계(Monotonic Clock) | OS의 “절대 뒤로 안 가는 시계”(CLOCK_MONOTONIC) 사용 — 경과 시간 측정엔 안전 | 언어 표준 라이브러리 |
| 마지막 발급 시각 기억 | 현재 시각이 그보다 작으면 거부/대기 — Snowflake의 핵심 방어선 | Snowflake, Sonyflake |
| 논리 시계(Lamport Clock) | 물리 시간 대신 “이벤트 카운터”를 시간으로 사용 — 인과관계 보장 | 분산 로그·합의 |
| 하이브리드 논리 시계 (HLC) | 물리 시계 + 논리 카운터 결합 — 시계가 어긋나도 인과관계 유지 | CockroachDB, MongoDB |
| TrueTime (Spanner) | GPS·원자시계로 “시간 구간”을 반환 — 불확실성 자체를 수치화 | Google Spanner |
| 윤초(Leap Second) 처리 | 윤초 삽입 시 시계가 1초 멈추거나 반복됨 → smearing(분산 처리) | Google, AWS |
Snowflake는 보통 NTP + 마지막 발급 시각 기억 두 가지로 충분히 운영된다. 더 강한 보장이 필요하면 HLC나 TrueTime 같은 상위 도구를 쓰는데, 이건 Snowflake의 영역을 넘어 분산 트랜잭션·합의 쪽으로 넘어간다.
운영의 함정 ② — 머신 ID와 일련번호
시계 다음으로 운영자가 신경 써야 하는 두 영역. 일련번호는 동작 자체가 단순하지만 4096 한계 처리가 필요하고, 머신 ID는 어떻게 안전하게 나눠줄지가 포인트다.
일련번호 동작
- 같은 머신, 같은 ms 안에서 0부터 1씩 증가
- ms가 바뀌면 0으로 리셋 (다음 ms의 ID는 다시 0부터)
- 12비트 → ms당 4096개까지 발급 가능
ms당 4096개를 초과하면? — 다음 ms까지 대기
드물지만 같은 머신에서 1ms 안에 4096개를 넘어 발급해야 할 때:
- 현재 ms의 일련번호가 4095에 도달 → 다음 ms가 될 때까지 busy-wait/sleep
- 다음 ms로 넘어가면 일련번호가 0으로 리셋되어 다시 발급 가능
- 현실적으로 머신당 초당 약 400만 개까지 가능하므로, 정상 트래픽에선 거의 도달하지 않음
머신 ID — 누가 부여하는가?
“데이터센터 ID(5비트) + 머신 ID(5비트) = 머신마다 고유한 10비트”를 어떻게 안전하게 나눠줄지가 운영 포인트.
| 방식 | 내용 | 트레이드오프 |
|---|---|---|
| 정적 설정 | 환경변수/설정파일에 머신 ID 박아둠 | 단순. 머신 추가/교체 시 사람이 관리 |
| Zookeeper / etcd | 부팅 시 코디네이터에서 미사용 ID 받아옴 | 자동 할당, 충돌 방지. 코디네이터 의존성 추가 |
| DB 시퀀스 | 중앙 DB에서 머신 ID auto_increment | 단순. 부팅 시점에 DB 의존 |
| 호스트명 해시 | 호스트명을 해시해서 10비트 추출 | 조율 불필요. 충돌 가능성(생일 문제) |
머신 ID 할당이 한 번만 일어나는 작업(부팅 시)이라는 점이 핵심. ID 발급 자체는 그 후 머신 로컬에서 빠르게 진행되므로, 코디네이터(Zookeeper)에 의존해도 ID 발급의 핫패스에는 영향 없음.
비트는 자유롭게 — 실제 변형 사례
“41/5/5/12”는 트위터의 답일 뿐, 비트 분배는 요구사항에 따라 자유롭게 조정된다. 실제 회사들이 어떻게 잘랐는지 보고, 인터랙티브로 직접 만져보자.
비트 분배는 “고정”이 아니다
총합이 64비트(부호 비트 제외 63비트)인 것만 고정이고, 그 안의 분배는 설계자의 선택이다. 비트는 제로섬이라 어딘가를 늘리면 다른 곳을 줄여야 한다.
| 영역 | +1비트 늘리면 |
|---|---|
| 타임스탬프 (41 → 42) | 사용 기간 2배 (~69년 → ~138년) |
| 데이터센터 ID (5 → 6) | DC 2배 (32 → 64개) |
| 머신 ID (5 → 6) | 머신 2배 (32 → 64대) |
| 일련번호 (12 → 13) | ms당 발급량 2배 (4096 → 8192) |
인터랙티브 — 비트 분배 플레이그라운드
“내가 운영할 시스템에 맞춰 어떻게 잘라야 하는가?”를 직접 만져보자. 운영 기간·DC 수·머신 수·발급 속도를 바꾸면 그에 필요한 최소 비트가 자동 계산되고, 64비트 예산 안에 들어가는지 즉시 확인할 수 있다.
🎛️ 비트 분배 플레이그라운드
요구사항을 바꾸면 그에 필요한 최소 비트가 자동 계산되고, 64비트 예산 안에 들어가는지 확인할 수 있다.
프리셋 버튼으로 Twitter 원본 / Discord(42비트) / Instagram(13비트 샤드) / Sonyflake(10ms 단위) / 소규모 서비스 설정을 바로 비교해 볼 수 있다.
실제 변형 사례 — 회사마다 다르게 자른다
Discord — 42 / 5 / 5 / 12 (1차 출처)
디스코드는 트위터 원본과 거의 같지만 타임스탬프가 42비트다. 공식 개발자 문서(Reference 섹션의 Snowflakes)에서 직접 확인 가능.
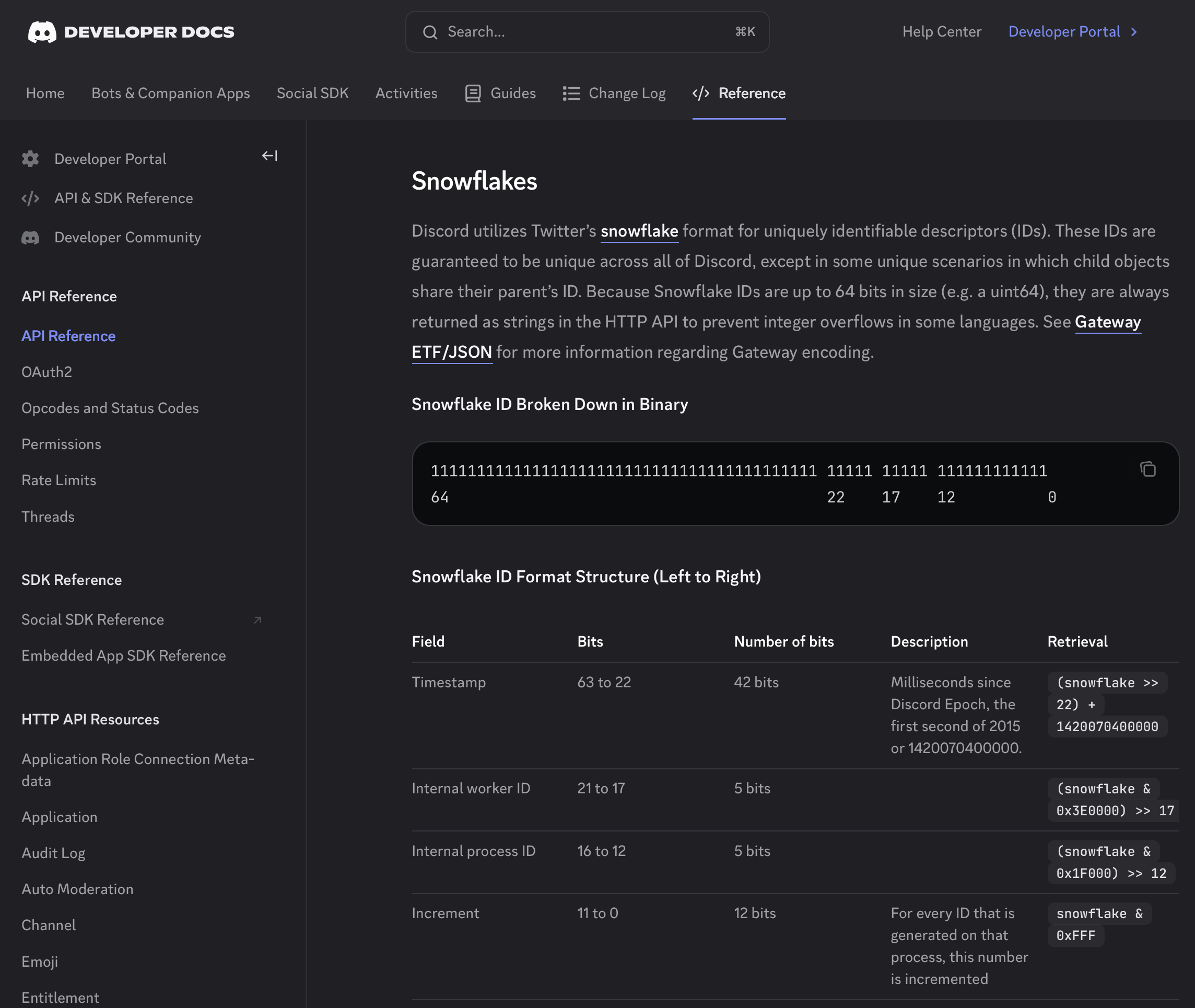
- Timestamp: 비트 63~22 → 42비트
- Internal worker ID: 비트 21~17 → 5비트
- Internal process ID: 비트 16~12 → 5비트
- Increment: 비트 11~0 → 12비트
- Discord epoch: 2015-01-01 (1420070400000ms)
- ※ Discord는
uint64를 사용해 부호 비트를 예약하지 않는다. 그래서 타임스탬프를 41비트가 아닌 42비트로 쓸 수 있다.
Instagram — 41 / 13 / 10
인스타그램은 PostgreSQL 함수로 ID를 생성한다. 머신/DC를 구분하지 않고 13비트 논리 샤드 ID로 합쳐 8192개 샤드를 표현, 일련번호는 10비트로 줄임.
출처: Instagram Engineering 블로그, “Sharding & IDs at Instagram” (2012)
Sony Sonyflake — 39 / 8 / 16
타임스탬프 39비트지만 단위가 10ms → 약 174년 사용 가능. 머신 ID 16비트로 65536대까지 지원하지만, 일련번호는 8비트로 작음 (10ms당 256개).
출처: GitHub sony/sonyflake 저장소 README
설계할 때 던지는 질문
- 얼마나 오래 쓸 시스템인가? 30년이면 충분 → 타임스탬프 줄이기 가능 / 100년 이상 → 늘리거나 단위를 10ms로 변경
- 얼마나 많은 머신/DC가 필요한가? 작은 회사: 머신 비트 줄여도 충분 / 대규모 글로벌: DC + 머신 비트 늘려야 함
- 순간 발급량(ms당 ID 수)은 얼마인가? 폭발적 트래픽: 일련번호 12비트 이상 / 일반 서비스: 8~10비트로 충분
마무리 — 실무에서 짚을 것들
핵심 설계가 끝났으니, 운영·확장 측면에서 추가로 다룰 주제들을 짚는다.
① 시계 동기화
앞서 강조했듯, Snowflake는 머신 시계에 의존한다. 모든 머신이 NTP로 맞춰져 있어야 하고, 시계 역행 처리 로직이 반드시 코드에 들어가야 한다.
② 비트 길이 조정
이미 변형 사례에서 본 것처럼, 41/5/5/12는 정답이 아니다. 운영 환경에 맞춰 비트를 재분배하라:
- 동시성이 낮다면 일련번호 비트를 줄이고 타임스탬프나 머신 ID를 늘려라
- 시스템을 100년 이상 쓸 거면 타임스탬프를 늘리거나 단위를 10ms로 (Sonyflake처럼)
- DC가 적다면 머신 ID로 합쳐서 더 많은 머신을 지원하라 (Instagram의 13비트 샤드 ID처럼)
③ 고가용성 (HA)
- ID 생성기를 독립 서비스로 배포할 경우, 여러 인스턴스를 돌려야 한다 (각 인스턴스는 서로 다른 머신 ID)
- “ID 생성기 자체”에 SPOF가 없도록 — Snowflake의 본질적 장점은 각 노드가 독립적으로 ID를 만든다는 것이므로, 운영도 그에 맞게 다중화
④ Snowflake가 아니어도 되는 경우
요구사항이 더 단순하면 Snowflake를 쓸 필요가 없다:
- “시간순 정렬은 필요 없고 유일성만 있으면 돼” → UUID면 충분
- “단일 DB로 트래픽이 감당된다” → 티켓 서버(auto_increment)로 충분
“요구사항 → 후보 비교 → 선택” 흐름을 면접에서 그대로 보여주는 것이 7장의 핵심.
핵심 한 줄
분산 ID는 “독립성 + 유일성 + 순서 + 작은 크기”라는 네 마리 토끼를 잡아야 하는 문제다. Snowflake는 비트 분할로 이를 한꺼번에 풀고, 나머지는 시계 동기화 + 머신 ID 부여 + 비트 재분배로 현장에 맞게 다듬는다.